
As companies continue to leverage AI based on Large Language Models (LLMs) to provide a better user experience, there is an increasing need to be aware of and protect against the risks associated with data leakage. This is particularly relevant for SaaS B2B companies that use LLMs in their service offerings, as these models can unintentionally reveal sensitive customer information, proprietary algorithms, and other confidential details through their responses. This risk is exacerbated when these models are trained on private data, and it becomes especially concerning when these models are made publicly available.
The Problem at Hand
Data leakage in LLMs often occurs due to several vulnerabilities, including:
- Incomplete or improper filtering of sensitive information in the LLM’s responses.
- Overfitting or memorization of sensitive data during the LLM’s training process.
- Unintended disclosure of confidential information due to LLM misinterpretation or errors.
One notable example of data leakage was demonstrated in a study that examined data extraction from OpenAI's GPT-2, a publicly available LLM. The research found that it was possible to extract specific pieces of training data that the model had memorized. By prompting the GPT-2 model with specific prefixes, the model was found to autocomplete with sensitive information, such as full names, phone numbers, and email addresses, that were included in the training data.
Interestingly, the study found that the larger the language model, the more easily it memorizes training data. This means that as LLMs continue to grow in size, the risk of data leakage also increases, necessitating more robust measures to monitor and mitigate this problem.
Another significant vulnerability that can lead to data leakage is prompt injection. This involves bypassing filters or manipulating the LLM using carefully crafted prompts, which can lead to unintended consequences, including data leakage and unauthorized access. By crafting prompts that manipulate the LLM into revealing sensitive information or bypassing restrictions, malicious actors can exploit this vulnerability to access confidential data.
The impact of these vulnerabilities is multiplied in systems or products that use LLM output to as input to another subsystem, thus creating a large blast radius for impact and data leakage.
Steps to Prevent Data Leakage
Companies can take several measures to prevent data leakage in LLMs, including:
- Implement strict output filtering to prevent the LLM from revealing sensitive information.
- Use differential privacy techniques or other data anonymization methods during the LLM’s training process to reduce the risk of overfitting or memorization.
- Regularly audit and review the LLM’s responses to ensure that sensitive information is not being disclosed inadvertently.
- Monitor and log LLM interactions to detect and analyze potential data leakage incidents.
In the case of prompt injection vulnerabilities, companies can:
- Implement strict input validation and sanitization for user-provided prompts.
- Use context-aware filtering and output encoding to prevent prompt manipulation.
- Regularly update and fine-tune the LLM to improve its understanding of malicious inputs and edge cases.
- Monitor and log LLM interactions to detect and analyze potential prompt injection attempts.
Context-Aware API Wrappers
A promising solution to protect against data leakage in LLMs lies in creating a context-aware layer around API libraries. This layer ensures by enforcing pre-defined policies that all calls are done under the right context, and all replies have the appropriate identifier in them. This protection is crucial in shared multi-tenant environments and prevents data from leaking from one customer to another while allowing sharing between users inside the same customer if that is required.
SuperTenant has developed a tenant-aware layer that closes this gap for SaaS companies without requiring dev cycles or maintenance headaches and allows for better compliance.
Let's analyze the recent data leak in OpenAI chatGPT, in which the service was taken offline due to a bug in an open-source Redis library which allowed some users to see titles from another active user’s chat history.
The source of the bug is a typical race condition:
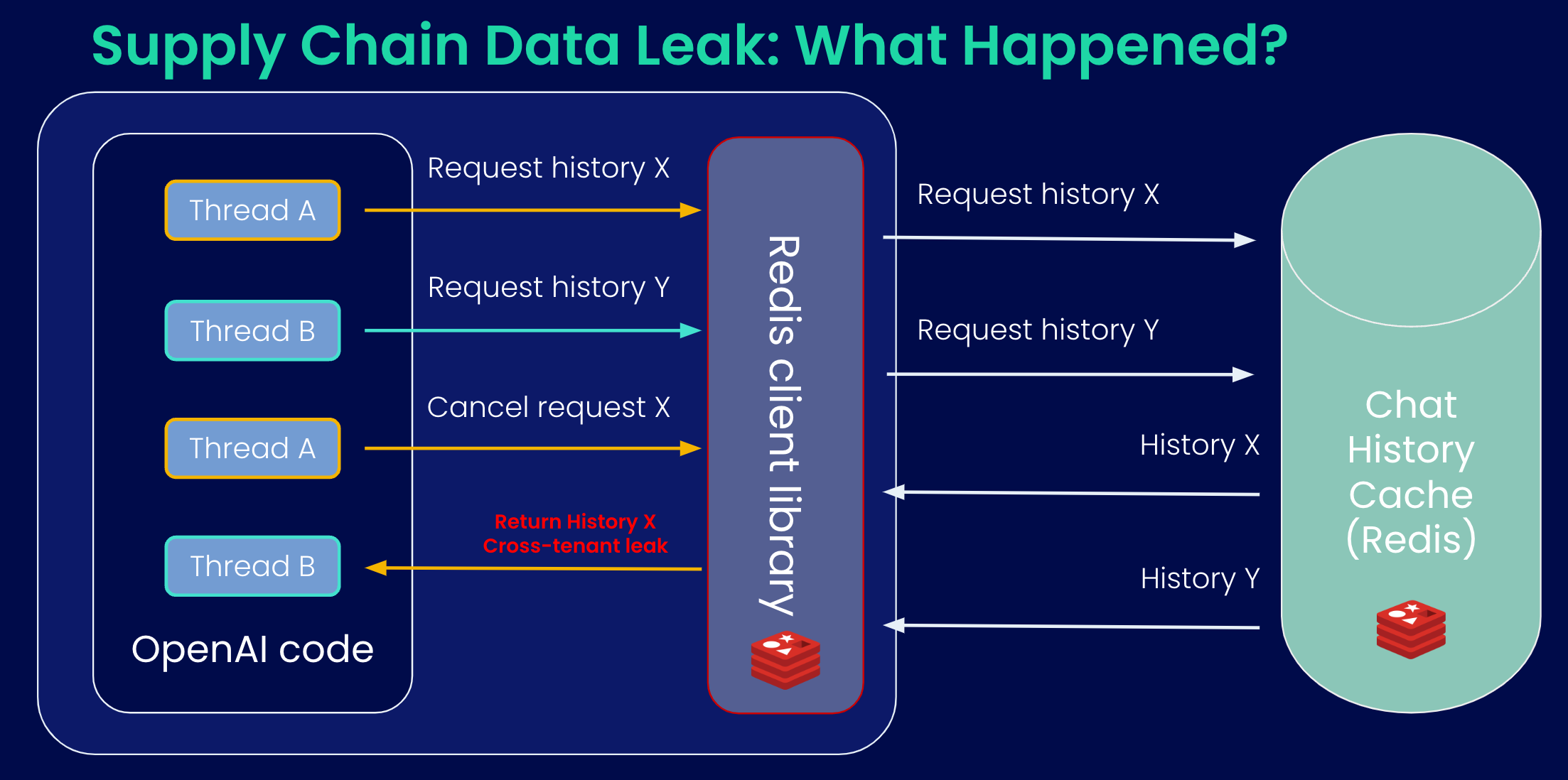
This race condition could not be caught by anything looking at the network level as it was a problem in the internal library.
The only way to identify and avoid this problem is by validating the contextual relevance of the data coming in from the library:
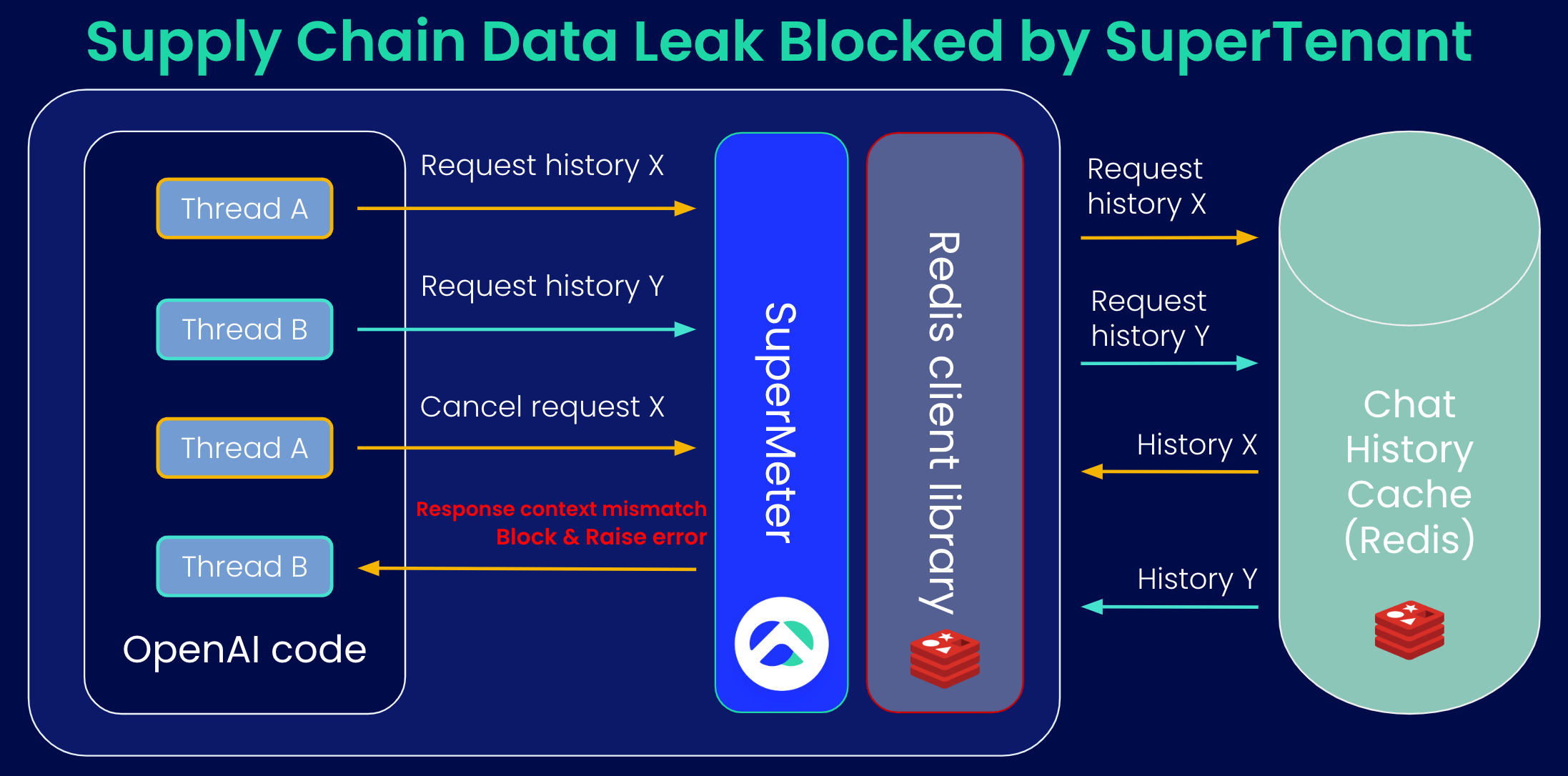
Conclusion
As LLMs continue to play a critical role in the services offered by SaaS companies, they carry significant data leakage risks, mitigating these risks involves several strategies. Implementing strict output filtering mechanisms can prevent the LLM from revealing sensitive information. Differential privacy techniques or other data anonymization methods during the LLM’s training process can reduce the risk of overfitting or memorization. Regular audits and reviews of the LLM’s responses can ensure that sensitive information is not being disclosed inadvertently, and monitoring and logging LLM interactions can detect and analyze potential data leakage incidents.
For prompt injection threats, it is recommended to implement strict input validation and sanitization for user-provided prompts and output encoding to prevent prompt manipulation.
While these strategies are effective, when considering the use of multi-tenant architectures, they do not protect against a leak from one customer to another, for this SaaS B2B companies should ensure that all calls are done under the right context and all replies are validated. SuperTenant can provide a real time solution to protect against these cases.
If you are interested in learning more about how SuperTenant can help - schedule a demo with us: